Hi Josh,
Ah, wow I completely overlooked that setting under the Queue General tab 😄
Thank you for pointing that out and for sharing the screenshot much appreciated!
We'll update a few selected queues to en-AU first and monitor whether this improves transcription accuracy for "Okta" and similar terms before making any broader changes.
Thanks again for the guidance.
------------------------------
Phaneendra
Technical Solutions Consultant
------------------------------
Original Message:
Sent: 03-19-2026 06:51
From: Josh Coyle
Subject: Copilot Transcription Accuracy – Should Trunk Language Match Dialect?
Hi Phaneendra,
The language can be set at queue level itself within the General tab of the Queue settings, image below:
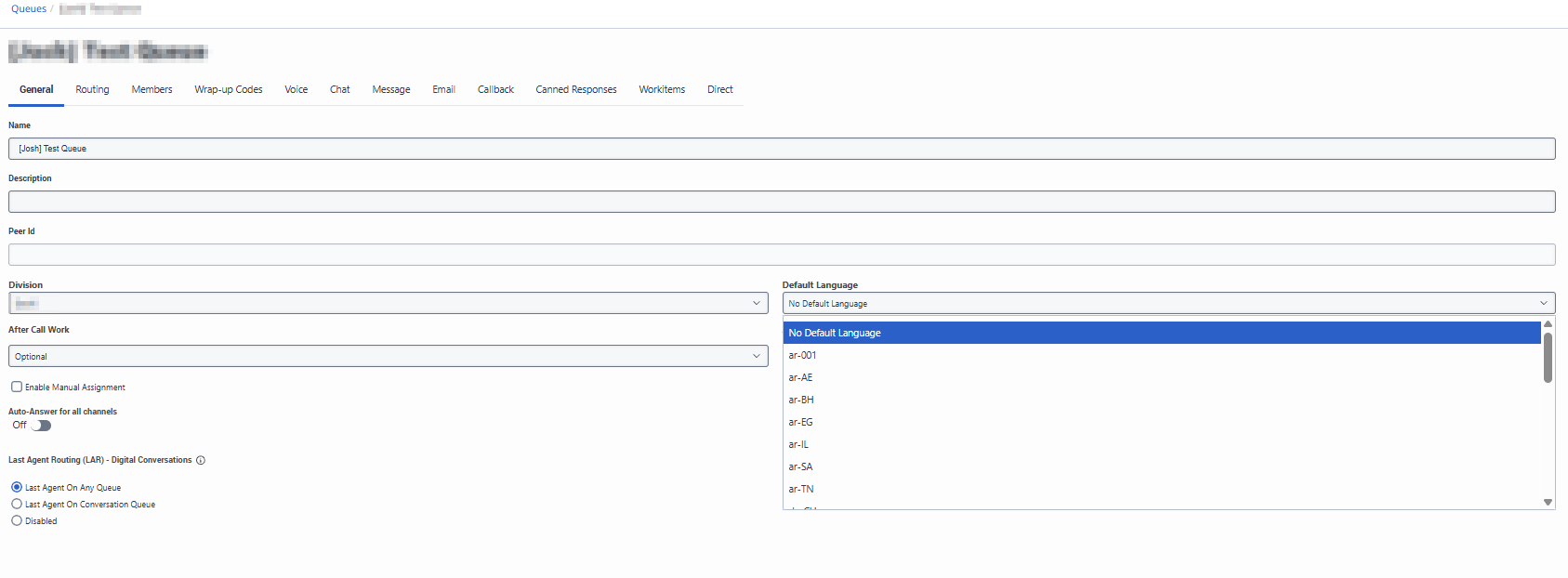
------------------------------
Josh Coyle
Senior Professional Services Consultant
------------------------------
Original Message:
Sent: 03-19-2026 06:39
From: Phaneendra Avatapalli
Subject: Copilot Transcription Accuracy – Should Trunk Language Match Dialect?
Hi Josh,
Thanks for the suggestion regarding the queue-level override.
We've already set the language to en-AU within our In-Queue flow (using the Set Language action), and our Dictionary Management is configured as en-AU.
I also have "Okta" configured in Dictionary Management, including phonetic variations such as "Octa" and other similar sound-like entries.
However, we don't currently see a separate Media Language or transcription language override option at the queue level.
Could you please clarify exactly where this queue-level override can be configured? Is this within the Queue configuration itself, or under Telephony/Trunks or Media Profiles which I don't have access to at the moment.
------------------------------
Phaneendra
Technical Solutions Consultant
Original Message:
Sent: 03-19-2026 06:08
From: Josh Coyle
Subject: Copilot Transcription Accuracy – Should Trunk Language Match Dialect?
Hi Phaneendra,
You're onto something with that dialect mismatch. You should be looking to have your trunk match your actual spoken dialect. Having en-US on the trunk but en-AU speakers is likely causing those "Okta" > "Octa" issues.
What some customers do is align everything to the dialect people actually speak (en-AU for you) and then use Dictionary Management with values to handle tricky branded terms.
Quick wins before touching the trunk:
------------------------------
Josh Coyle
Senior Professional Services Consultant